
Santiago Matiz
Abril 7 del 2022 – 1 Min de Lectura
Particionamiento de tablas postgresql

Muchas veces nuestras tablas en postgresql alcanzan un número de registros suficientemente grande creando un problema del desempeño en las consultas.
Por más que intentemos aumentar el desempeños con estrategias de indices ,no lo lograremos ya que el número de registros en inmenso.
Existe una técnica que consiste en dividir o distribuir los registros en varias tablas logrando un desempeño mayor, pero … si no se sabe hacer lo que se obtiene es frustración en el proceso.
Veamos en este articulo cómo se debe hacer :
Desde la versión 10 de Postgresql, se crea la opción de particionar las tablas de una manera más fácil, antes de esta versión se debía generar cada una de las tablas y a partir de trigger comenzar a gestionar la inversión de cada uno de los registros.
Comencemos con el siguiente ejemplo sencillo:
Tenemos varios usuario y estos estás distribuidos en diferentes países, sencillamente son tres países para nuestro ejemplo.
Antes de mostrar las instrucciones para la creación de tabla se hacer los análisis de las sentencias SQL para tomar la decisión de como vamos a particionar las tablas.
En el caso de tabla de usuario los querys hacen un filtro por país por lo que es ideal particionar por este campo.
veamos por que:
Creamos una tabla de usuario y le decimos que la particionamos por el país
Creación de las tablas
CREATE TABLE usuarios (
user_id int not null,
user_email varchar(50) not null,
logdate date not null,
country varchar(30) not null
) PARTITION BY LIST (country);
CREATE TABLE usuario_col PARTITION OF usuarios FOR VALUES IN (‘COL’);
CREATE TABLE usuario_per PARTITION OF usuarios FOR VALUES IN (‘PER’);
CREATE TABLE usuario_ecu PARTITION OF usuarios FOR VALUES IN (‘ECU’);

Insertemos los siguientes registros :
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (1, ‘usario1@mail.com’, ‘2001-01-01’, ‘COL’);
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (2, ‘usario2@mail.com’, ‘2002-01-01’, ‘COL’);
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (3, ‘usario3@mail.com’, ‘2003-01-01’, ‘ECU’);
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (4, ‘usario4@mail.com’, ‘2004-01-01’, ‘PER’);
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (5, ‘usario5@mail.com’, ‘2005-01-01’, ‘ECU’);
INSERT INTO public.usuarios(user_id, user_email, logdate, country) VALUES (6, ‘usario6@mail.com’, ‘2006-01-01’, ‘COL’);
Análisis
Ejercicio 1
EXPLAIN SELECT * FROM usuarios
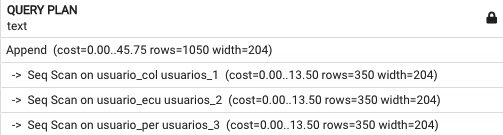
Obtenemos un costos de 45.75
Lo que nos muestra el análisis, es que debe recorrer cada una de las tablas particionadas…
Ejercicio 2
EXPLAIN SELECT * FROM usuarios WHERE country=’COL’
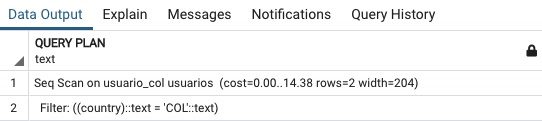
Obtenemos un costos de 14.38, lo cual es una mejora considerable
Ejercicio 3
Ahora veamos el siguiente query filtrando por un criterio no particionado ,
Explain select * from usuarios WHERE logdate=’2004-01-01′
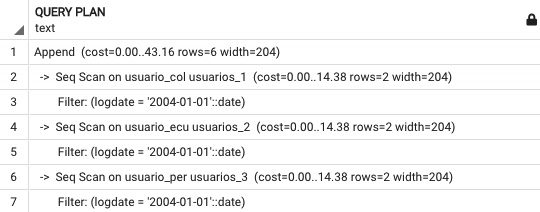
Obtenemos un costo de 43.16, muy similar a tener un query sin filtros
Conclusión
Podemos concluir: particionamos de acuerdo a un análisis de las SENTENCIAS de SQL y por esta razón logramos incrementar un desempeño considerable en los querys, buscando por el criterio del particionamiento.
Si por lo contrario se hubiera particionado por fecha , y el uso de los querys necesita recorrer todas las tablas para encontrar los registros, el resultado es nefasto.
Referencias
Encuentra más información en: